22 KiB
| author | link | date |
|---|---|---|
| https://www.figma.com/blog/how-figmas-multiplayer-technology-works/ | August 1, 2023 |
How Figma’s multiplayer technology works | Figma Blog
#technology #design #collaboration
When we first started building multiplayer functionality
in Figma four years ago, we decided to develop our own solution. No other design tool offered this feature, and we didn’t want to use operational transforms (a.k.a. OTs), the standard multiplayer algorithm popularized by apps like Google Docs. As a startup we value the ability to ship features quickly, and OTs were unnecessarily complex for our problem space. So we built a custom multiplayer system thats simpler and easier to implement.

At the time, we weren’t sure building this feature was the right product decision. No one was clamoring for a multiplayer design tool—if anything, people hated the idea. Designers worried that live collaborative editing would result in “hovering art directors” and “design by committee” catastrophes.
But ultimately, we had to do it because it just felt wrong not to offer multiplayer as a tool on the web. It eliminates the need to export, sync, or email copies of files and allows more people to take part in the design process (like copy-writers and developers). Just by having the right link, everyone can view the current status of a design project without interrupting the person doing the work.
Our bet paid off, and these days it’s obvious that multiplayer is the way all productivity tools on the web should work, not just design. But while we use products with live collaborative editing every day, there aren’t that many public case studies on these production systems.
We decided it was time to share a peek into how we did it at Figma, in the hopes of helping others. It should be a fun read for those who like seeing how computer science theory is applied in practice. We’ll cover a lot but each section builds upon the previous ones. By the end, you should hopefully have an understanding of the entire system.
Background context: Figma’s setup, OTs, and more
Before talking about our multiplayer protocol, its useful to have some context about how our multiplayer system is set up. We use a client/server architecture where Figma clients are web pages that talk with a cluster of servers over WebSockets. Our servers currently spin up a separate process for each multiplayer document which everyone editing that document connects to. If you’re interested in learning more, this article talks about how we scale our production multiplayer servers.

When a document is opened, the client starts by downloading a copy of the file. From that point on, updates to that document in both directions are synced over the WebSocket connection. Figma lets you go offline for an arbitrary amount of time and continue editing. When you come back online, the client downloads a fresh copy of the document, reapplies any offline edits on top of this latest state, and then continues syncing updates over a new WebSocket connection. This means that connecting and reconnecting are very simple and all of the complexity with multiplayer (which is what this blog post is about) is in dealing with updates to already connected documents.
It’s worth noting that we only use multiplayer for syncing changes to Figma documents. We also sync changes to a lot of other data (comments, users, teams, projects, etc.) but that is stored in Postgres, not our multiplayer system, and is synced with clients using a completely separate system that won’t be discussed in this article. Although these two systems are similar, they have separate implementations because of different tradeoffs around certain properties such as performance, offline availability, and security.
We didnt start with this setup though. When making a change this fundamental, its important to be able to iterate quickly and experiment before committing to an approach. Thats why we first created a prototype environment to test our ideas instead of working in the real codebase. This playground was a web page that simulated three clients connecting to a server and visualized the whole state of the system. It let us easily set up different scenarios around offline clients and bandwidth limited connections.
Once we figured out how we wanted to build our multiplayer system, it was straightforward to graft the ideas from our prototype onto our existing codebase. We used this prototype to quickly research and evaluate different collaborative algorithms and data structures.
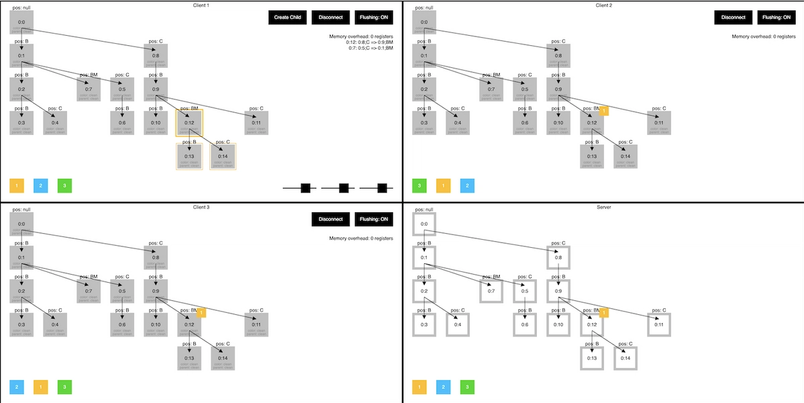
A screenshot of our internal prototype

Douglas Engelbart practicing for "The Mother of All Demos"
How OTs and CRDTs informed our multiplayer approach
Multiplayer technology has a rich history and has arguably been around at least since Douglas Engelbarts demo in 1968. Before we dive in too deep into how our own multiplayer system works, it’s worth a quick overview on the traditional approaches that informed ours: OTs and CRDTs.
Critique of OT
While the classic OT approach of defining operations through their offsets in the text seems to be simple and natural, real-world distributed systems raise serious issues. Namely, that operations propagate with finite speed, states of participants are often different, thus the resulting combinations of states and operations are extremely hard to foresee and understand. As Li and Li put it, "Due to the need to consider complicated case coverage, formal proofs are very complicated and error-prone, even for OT algorithms that only treat two characterwise primitives (insert and delete)."
As mentioned earlier, OTs power most collaborative text-based apps such as Google Docs. They’re the most well-known technique but in researching them, we quickly realized they were overkill for what we wanted to achieve. They’re a great way of editing long text documents with low memory and performance overhead, but they are very complicated and hard to implement correctly. They result in a combinatorial explosion of possible states which is very difficult to reason about.
Our primary goal when designing our multiplayer system was for it to be no more complex than necessary to get the job done. A simpler system is easier to reason about which then makes it easier to implement, debug, test, and maintain. Since Figma isnt a text editor, we didnt need the power of OTs and could get away with something less complicated.
Conflict-free replicated data type
In distributed computing, a conflict-free replicated data type (CRDT) is a data structure that is replicated across multiple computers in a network, with the following features:
- The application can update any replica independently, concurrently and without coordinating with other replicas.
- An algorithm (itself part of the data type) automatically resolves any inconsistencies that might occur.
- Although replicas may have different state at any particular point in time, they are guaranteed to eventually converge.
Figmas tech is instead inspired by something called CRDTs, which stands for conflict-free replicated data types. CRDTs refer to a collection of different data structures commonly used in distributed systems. All CRDTs satisfy certain mathematical properties which guarantee eventual consistency. If no more updates are made, eventually everyone accessing the data structure will see the same thing. This constraint is required for correctness; we cannot allow two clients editing the same Figma document to diverge and never converge again.
There are many types of CRDTs. See this list for a good overview. Some examples:
- Grow-only set: This is a set of elements. The only type of update is to add something to the set. Adding something twice is a no-op, so you can determine the contents of the set by just applying all of the updates in any order.
- Last-writer-wins register: This is a container for a single value. Updates can be implemented as a new value, a timestamp, and a peer ID. You can determine the value of the register by just taking the value of the latest update (using the peer ID to break a tie).
Figma isnt using true CRDTs though. CRDTs are designed for decentralized systems where there is no single central authority to decide what the final state should be. There is some unavoidable performance and memory overhead with doing this. Since Figma is centralized (our server is the central authority), we can simplify our system by removing this extra overhead and benefit from a faster and leaner implementation.
It’s also worth noting that Figmas data structure isnt a single CRDT. Instead its inspired by multiple separate CRDTs and uses them in combination to create the final data structure that represents a Figma document (described below).
Even if you have a client-server setup, CRDTs are still worth researching because they provide a well-studied, solid foundation to start with. Understanding them helps build intuition on how to create a correct system. From that point, its possible to relax some of the requirements of CRDTs based on the needs of the application as we have done.
How a Figma document is structured
Ok, so we want to sync updates to Figma documents using CRDTs. What does the structure of a Figma document even look like?
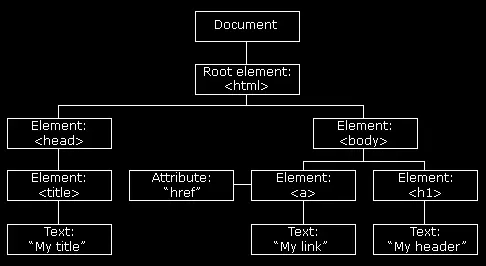
HTML DOM
The HTML Document Object Model (DOM) is a standard object model and programming interface for HTML. It defines: The HTML elements as objects, the properties of all HTML elements, the methods to access all HTML elements, and the events for all HTML elements.
Every Figma document is a tree of objects, similar to the HTML DOM. There is a single root object that represents the entire document. Underneath the root object are page objects, and underneath each page object is a hierarchy of objects representing the contents of the page. This tree is is presented in the layers panel on the left-hand side of the Figma editor.
Each object has an ID and a collection of properties with values. One way to think about this is by picturing the document as a two-level map: Map<ObjectID, Map<Property, Value>>. Another way to think about this is a database with rows that store (ObjectID, Property, Value) tuples. This means that adding new features to Figma usually just means adding new properties to objects.
The details of Figma’s multiplayer system
For the rest of this post, we will talk about the details of Figmas multiplayer algorithm and how we solved some of the edge cases we encountered.
Syncing object properties
Figma’s multiplayer servers keep track of the latest value that any client has sent for a given property on a given object. This means that two clients changing unrelated properties on the same object won’t conflict, and two clients changing the same property on unrelated objects also won’t conflict. A conflict happens when two clients change the same property on the same object, in which case the document will just end up with the last value that was sent to the server. This approach is similar to a last-writer-wins register in CRDT literature except we don’t need a timestamp because the server can define the order of events.
An animation showing two clients sending updates without any conflicts
An important consequence of this is that changes are atomic at the property value boundary. The eventually consistent value for a given property is always a value sent by one of the clients. This is why simultaneous editing of the same text value doesn’t work in Figma. If the text value is B and someone changes it to AB at the same time as someone else changes it to BC, the end result will be either AB or BC but never ABC. That’s ok with us because Figma is a design tool, not a text editor, and this use case isn’t one we’re optimizing for.
The most complicated part of this is how to handle conflicts on the client when there’s a conflicting change. Property changes on the client are always applied immediately instead of waiting for acknowledgement from the server since we want Figma to feel as responsive as possible. However, if we do this and we also apply every change from the server as it comes in, conflicting changes will sometimes “flicker” when older acknowledged values temporarily overwrite newer unacknowledged ones. We want to avoid this flickering behavior.
Intuitively, we want to show the user our best prediction of what the eventually-consistent value will be. Since our change we just sent hasn’t yet been acknowledged by the server but all changes coming from the server have been, our change is our best prediction because it’s the most recent change we know about in last-to-the-server order. So we want to discard incoming changes from the server that conflict with unacknowledged property changes.
An animation showing how to avoid “flickering” during a conflict between two clients
Syncing object creation and removal
Creating a new object and removing an existing object are both explicit actions in our protocol. Objects cannot automatically be brought into existence by writing a property to an unassigned object ID. Removing an object deletes all data about it from the server including all of its properties.
Object creation in Figma is most similar to a last-writer-wins set in CRDT literature, where whether an object is in the set or not is just another last-writer-wins boolean property on that object. A big difference from this model is that Figma doesn’t store any properties of deleted objects on the server. That data is instead stored in the undo buffer of the client that performed the delete. If that client wants to undo the delete, then it’s also responsible for restoring all properties of the deleted objects. This helps keep long-lived documents from continuing to grow in size as they are edited.
This system relies on clients being able to generate new object IDs that are guaranteed to be unique. This can be easily accomplished by assigning every client a unique client ID and including that client ID as part of newly-created object IDs. That way no two clients will ever generate the same object ID. Note that we can’t solve this by having the server assign IDs to newly-created objects because object creation needs to be able to work offline.
Syncing trees of objects
Arranging objects in an eventually-consistent tree structure is the most complicated part of our multiplayer system. The complexity comes from what to do about reparenting operations (moving an object from one parent to another). When designing the tree structure, we had two main goals in mind:
- Reparenting an object shouldn’t conflict with changes to unrelated properties on those objects. If someone is changing the object’s color while someone else is reparenting the object, those two operations should both succeed.
- Two concurrent reparenting operations for the same object shouldn’t ever result in two copies of that object in separate places in the tree.
Many approaches represent reparenting as deleting the object and recreating it somewhere else with a new ID, but that doesnt work for us because concurrent edits would be dropped when the objects identity changes. The approach we settled on was to represent the parent-child relationship by storing a link to the parent as a property on the child. That way object identity is preserved. We also don’t need to deal with the situation where an object somehow ends up with multiple parents that we might have if, say, we instead had each parent store links to its children.
However, we now have a new problem. Without any other restrictions, these parent links are just directed edges on a graph. There’s nothing to ensure that they have no cycles and form a valid tree. An example of this is a concurrent edit where one client makes A a child of B while another client makes B a child of A. Then A and B are both each other’s parent, which forms a cycle.
Figma’s multiplayer servers reject parent property updates that would cause a cycle, so this issue can’t happen on the server. But it can still happen on the client. Clients can’t reject changes from the server because the server is the ultimate authority on what the document looks like. So a client could end up in a state where it has both sent the server an unacknowledged change to parent A under B and also received a change from the server that parents B under A. The client’s change will be rejected in the future by the server because it will form a cycle, but the client doesn’t know it yet.
An animation of a reparenting conflict
Figma’s solution is to temporarily parent these objects to each other and remove them from the tree until the server rejects the client’s change and the object is reparented where it belongs. This solution isn’t great because the object temporarily disappears, but it’s a simple solution to a very rare temporary problem so we didn’t feel the need to try something more complicated here such as breaking these temporary cycles on the client.
To construct a tree we also need a way of determining the order of the children for a given parent. Figma uses a technique called “fractional indexing” to do this. At a high level, an object’s position in its parent’s array of children is represented as a fraction between 0 and 1 exclusive. The order of an object’s children is determined by sorting them by their positions. You can insert an object between two other objects by setting its position to the average of the positions of the two other objects.
An animation of reordering using fractional indexing
We’ve already written another article that describes this technique in detail. The important part to mention here is that the parent link and this position must both be stored as a single property so they update atomically. It doesn’t make sense to continue to use the position from one parent when the parent is updated to point somewhere else.
Implementing undo
Undo history has a natural definition for single-player mode, but undo in a multiplayer environment is inherently confusing. If other people have edited the same objects that you edited and then undo, what should happen? Should your earlier edits be applied over their later edits? What about redo?
We had a lot of trouble until we settled on a principle to help guide us: if you undo a lot, copy something, and redo back to the present (a common operation), the document should not change. This may seem obvious but the single-player implementation of redo means “put back what I did” which may end up overwriting what other people did next if you’re not careful. This is why in Figma an undo operation modifies redo history at the time of the undo, and likewise a redo operation modifies undo history at the time of the redo.
An animation showing undo and redo history modification
The big takeaways
Weve covered a lot! This is the post we wished we could have read when we were first starting our research. Its one thing to learn about CRDTs in the abstract, but its a different thing to find out how those ideas work in practice in a real production system.
Some of our main takeaways:
- CRDT literature can be relevant even if youre not creating a decentralized system
- Multiplayer for a visual editor like ours wasnt as intimidating as we thought
- Taking time to research and prototype in the beginning really paid off
If you made it this far, you should now have enough information to make your own collaborative tree data structure. And even if your problem space isnt exactly like ours, I hope this post shows how CRDT research can be a great source of inspiration.
Do you love thinking about collaborative editing, distributed systems, or building scalable services? We’re hiring!
Hero illustration by Rose Wong.